

系列笔记:斯坦福公开课 CS146S: The Modern Software Developer,主讲人 Mihail Eric。前几讲我们从LLM原理讲到Prompt工程,再到从零搭Agent和MCP协议,这一讲落地到每个开发者每天都在用的东西——IDE。

我用IDE这件事,算是有点年头了。
早年写Java,用的是当时刚出来的Eclipse,第一次看到”代码自动补全”这个功能,觉得真棒——它能预测我要打的下一个单词。后来用IntelliJ IDEA,重构、跳转、静态分析,整套工具链帮你把很多低级错误在运行之前就拦截掉。再后来VS Code横空出世,轻量、快、插件生态爆炸,很快成了大多数人的默认选择。
每一代IDE更替,本质上都在做一件事:把开发者从重复的、机械的工作里解放出来,让他们更专注于真正需要思考的事情。
Cursor在2023年出现,走的是同一条路,到现在AI Coding IDE百家齐放,(参考我之前的文章三款主流AI编程工具对比:Claude Code、Google Antigravity、OpenAI Codex)但这一次迈出去的步子,比以前大得多。
IDE四十年,一条清晰的进化线
Mihail 在这一讲开头放了一条时间线,从1983年的Turbo Pascal一直拉到今天。我觉得这条时间线值得认真看一下,因为它揭示了一个规律:
1983年,Turbo Pascal——第一个真正意义上的IDE。把编辑器、编译器、调试器塞进一个工具里,开发者第一次不需要在多个程序之间来回切换。
1997年,Microsoft Visual Studio——把调试能力做到了极致,尤其是C++和Visual Basic。大型工程的开发效率大幅提升。
2001年,IntelliJ IDEA——智能代码导航、自动重构、上下文感知的代码补全。IDE开始真正”理解”代码,而不只是”编辑”代码。
2015年,VS Code——反其道而行之,轻量化,把扩展能力开放给社区。结果社区爆发出惊人的能量,几年内几乎统治了整个编辑器市场。
2023年,Cursor——AI原生IDE。不是给现有IDE加一个AI插件,而是从一开始就把AI能力设计进工具的骨子里。
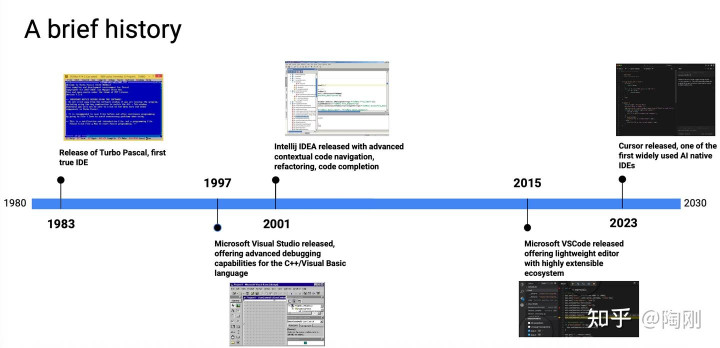
每一步都是在回答同一个问题:怎么让工具更懂你在做什么? 不同的是,这一次”懂”的程度,突破了以往所有工具的天花板。
AI IDE能做什么:从基础到进阶
Mihail把AI IDE的使用方式分成两层:
基础层(Bread-and-butter),是你每天都在用的那几个动作:
行内补全(Inline)——你在打代码,它预测你接下来要写什么,按Tab就能接受。这是大多数人对AI IDE的第一印象,也是最高频的功能。
函数级生成(Function)——你描述一个函数要做什么,它帮你把整个函数体写出来。
单文件编辑(Single-file)——在一个文件范围内进行修改,加功能、改逻辑、重构。
多文件编辑(Multi-file)——跨多个文件同时修改,这是传统IDE很难做到的。一个需求可能涉及接口定义、实现、测试、文档,AI IDE可以一次性跨文件协调。
进阶层(True AI-native),是让AI IDE真正区别于”加了AI插件的普通IDE”的能力:
后台Agent——你告诉它一个任务,它自己在后台跑,不需要你盯着。你去喝杯咖啡,回来看结果。
MCP集成——上一讲讲过的,让Agent能直接连接外部数据源和工具。
记忆(Memories)——它能记住你们之前的对话和偏好,下次不需要重新解释背景。
PR审查(Bugbot)——它能自动扫描你的Pull Request,找出潜在的问题,就像有一个随时待命的code reviewer。
揭开盖子:AI IDE的底层机制
这部分是我觉得这一讲最有价值的地方。大多数人用Cursor或者Copilot,知其然不知其所以然,Mihail把底层机制讲得很清楚。
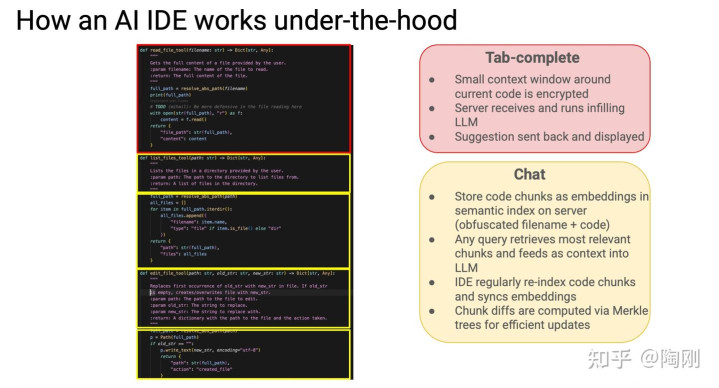
Tab补全是怎么工作的?
你在打代码的时候,IDE会把你当前光标周围的一小段代码加密发送给服务器。服务器用一个专门为”代码填空”训练的LLM(infilling model)来预测你接下来要写什么,把建议发回来,显示在你的光标后面。
整个过程在几十到几百毫秒内完成,速度要求极高,所以用的通常是专门为低延迟优化的小模型,而不是GPT-4这种大炮。
Chat功能是怎么工作的?
这里的实现就复杂多了,核心是一套语义索引系统:
IDE把你的整个代码库切成一段一段的chunk(代码片段),把每个chunk转换成高维向量(embedding),存在服务器的语义索引里。文件名会被混淆处理,保护隐私。
当你在Chat里问一个问题,系统先把你的问题也转成向量,然后在索引里做相似度搜索,找出和你的问题最相关的那些代码片段,把它们作为上下文一起喂给LLM。
为了保持索引的新鲜度,IDE会定期重新索引代码变更。更新的效率很讲究:用Merkle Tree来计算哪些chunk真正发生了变化,只更新有差异的部分,而不是每次全量重建。
Merkle Tree 是一种树形数据结构,核心思想是用哈希值来高效验证数据有没有被改动。
从底部往上理解
想象你有四个文件:A、B、C、D。
第一步: 对每个文件计算一个哈希值(一种把任意内容压缩成固定长度指纹的算法):
Hash(A) Hash(B) Hash(C) Hash(D)
第二步: 把相邻的哈希值两两合并,再哈希一次:
Hash(AB) = Hash( Hash(A) + Hash(B) )
Hash(CD) = Hash( Hash(C) + Hash(D) )
第三步: 继续往上合并,直到只剩一个根哈希值(Root Hash):
Root = Hash( Hash(AB) + Hash(CD) )
整棵树长这样:
Root
/ \
Hash(AB) Hash(CD)
/ \ / \
H(A) H(B) H(C) H(D)
哈希有一个关键特性:输入只要有一个字节改变,输出就完全不同。
所以如果文件 B 被改动了,Hash(B) 会变,Hash(AB) 会变,Root 也会变。你只需要比较 Root 就能知道"有东西变了",然后顺着树往下找,很快就能定位到是哪个文件出了问题。
这就是为什么 Merkle Tree 适合做增量更新——不需要检查所有文件,只需要比较哈希,路径短、速度快。
这最后一点让我多想了一下。Merkle Tree在分布式系统里很常见,Git就在用它来追踪文件变更,区块链也在用。在这里用来做增量embedding更新,是一个很聪明的工程选择——代码库大起来之后,全量重建的成本是完全不可接受的。
用好AI IDE的关键:你得先成为一个好的PM
这一讲让我印象最深的,是Mihail说的这句话:
对于复杂的任务,你需要成为一个产品经理。
他说的不是比喻,是字面意思。
简单任务——改个变量名、加一行注释、修一个明显的typo——随手写一句就行,AI IDE能轻松搞定。
但稍微复杂一点的任务,如果你只是扔给AI一句模糊的需求,它给你的结果十有八九不是你想要的。不是因为模型不够聪明,而是因为它没有足够的信息来做出正确的决策。
Mihail给了一个他在实际项目里用的Spec文档模板,我觉得这是这一讲最实用的干货:
Goal(目标):这次改动的目的是什么?解决什么问题?
Definitions(定义):LLM需要了解哪些背景知识?项目里有没有特殊的术语或约定?
Plan(计划):高层次的实现思路是什么?分哪几步走?
Source files(相关文件):哪些文件会被改动?为什么?
Test cases(测试用例):怎么验证改动是正确的?
Edge cases(边界情况):有哪些特殊情况需要处理?
Out-of-scope(不在范围内):什么东西不应该被改动?这一条极其重要——AI很容易”好心办坏事”,帮你顺手改了你不想改的东西。
Extensions(未来扩展):未来可能有哪些相关改动?让AI设计时留好扩展点,而不是走捷径留下死路。
写这份Spec的过程本身,其实也是在强迫你把需求想清楚。你连Edge case都没想过,那不是AI的问题,是你自己的问题。
为AI优化你的代码仓库
这一讲还有一个很有价值的视角转换:不只是你去适应AI IDE,你的代码仓库也要为AI优化。
Mihail说,LLM出现混乱和错误,很多时候不是模型的锅,而是它拿到的上下文太乱了——杂乱的目录结构、缺失的注释、不一致的命名、没有文档的API契约。一个对人类工程师来说”勉强能看懂”的代码库,对AI来说可能完全是噩梦。
他建议在代码库里提供这些信息:仓库的整体介绍、目录结构说明、环境配置和启动方式、代码风格规范、常用的API和契约定义,以及访问模式(什么情况下用哪个模块)。
而且他特别推荐Monorepo架构——把相关的代码放在一个仓库里,而不是分散在多个repo。对AI来说,能在一个上下文里看到前端、后端、基础库的完整代码,比在多个仓库之间来回跳要友好得多。
具体的实现方式,现在各家工具有各自的约定:
CLAUDE.md:Claude自动读取的上下文文件,适合放常用命令、核心文件说明、代码风格要求、测试方法
cursorrules:Cursor的规则文件,类似功能
AGENTS.md:开放格式,通用性更强
llms.txt:给爬取你网站的LLM提供导航信息,类似robots.txt,但面向AI而非搜索引擎
有一点要注意:Mihail提醒,这些配置文件只是”建议”,不是”命令”。AI不保证会百分之百遵守。但有总比没有好,至少给了模型一个更好的起点。
小结
四十年前,IDE帮开发者把编辑、编译、调试整合到一个地方。今天,AI IDE在做同样的事情——只不过这次整合进来的,是一个能理解自然语言、能生成代码、能跨文件推理的AI协作者。
但这个协作者需要好的上下文才能发挥作用。代码库要整洁、文档要到位、需求要说清楚。这些听起来是”理所当然”的工程基本功,但现实里的代码库,又有几个真的做到了?
AI IDE的出现,以一种意想不到的方式,把我们倒逼回了软件工程最基础的问题:你的系统,真的有人能看懂吗?
系列笔记持续更新。课程资料参考:themodernsoftware.dev,斯坦福 CS146S,主讲人 Mihail Eric。
星速优配提示:文章来自网络,不代表本站观点。



